In het vorige bericht is gesproken over het dynamisch maken van de gateway op een server. Na de setup is er een aanpassing gemaakt om de statische default-route uit te schakelen. Een bijkomend nadelig effect is dat bij een herstart van de server deze onbereikbaar maakt. Waarom? Omdat de FRR daemon start en het netwerk nog niet gereed is en het dus een fout oploopt en faalt. Dus dan raak je aan een console sessie of wellicht DRAC/ILO of misschien wel een fysiek bezoek.
Een oplossing kan in het systemd ecosysteem gevonden worden. Er zijn zelfs 2 (misschien wel meer) manieren mogelijk.
De eerste is een simpele delay timer. Met systemctl edit frr.service kan je aanpassingen maken (zijnde override). Voeg het onderstaande toe onder de eerste 2 (commented) regels:
[Service]
ExecStartPre=/bin/sleep 5
Sla het op en klaar. Maar: wat als het opstarten van netwerk te lang duurt? De timer omhoog is een manier maar niet heel robuust. Het kan ook misschien langer duren dan nodig is, of ook weer falen.
Het kan ook op de volgende manier, in dezelfde edit modus van de systemctl met de FRR service.
Hiermee koppel je de FRR service aan de systemd-networkd service en word pas gestart als het netwerk gereed is. Eigenlijk is de After voldoende maar de BindsTo is een andere praktische oplossing. Als iets of iemand het netwerk op de server herstart, word FRR meegenomen in de herstart!
In sommige situaties heb je bij een ISP het zo dat zij geen first-hop-redundacy protocol , zoals HSRP of VRRP, ondersteunen maar wel op een 2-tal edgerouters een gateway voor jou aanbieden binnen hetzelfde subnet. In dit artikel duik ik een klein stukje in het gebruik van BGP en de BGP mogelijkheden op Linux binnen FRRrouting (FRR). Een setup die bij grote cloudproviders ook veel gebruikt kan worden.
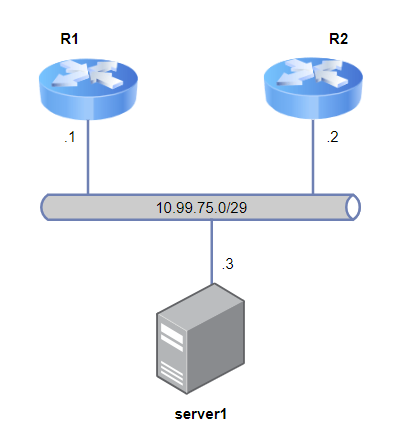
Een situatie schets van het netwerk:
In deze situatie zou je een default gateway kunnen zetten naar 1 router. Ja, natuurlijk kan je een 2e zetten maar bij uitval of onderhoud van een router heb je daar last van (de server weet namelijk niet welke route er gekozen moet worden). Een dynamisch protocol als BGP heeft dat nadeel niet.
We gaan even uit van een minimaal geinstalleerde Ubuntu 22.04 LTS server. Deze heeft R1 als default-gateway om van basis connectiviteit te voorzien. We gaan daarna FRR via de cli installeren en configureren. Ook zetten we de BGP-daemon aan:
apt install -y frr frr-pythontools
sed -i "s/^bgpd=no/bgpd=yes/" /etc/frr/daemons
Hierna kunnen we een eenvoudige BGP-setup in de configuratie opnemen op de server. De routers van de ISP leven in dit voorbeeld in ASN 65001 en wij hebben vanuit onze ISP ASN 65015 toegekend gekregen. We staan via een prefix-list alleen de default-route toe.
Nu deze configuratie staat kunnen we de daemon starten:
systemctl restart frr
In ons geval heeft onze ISP de configuratie op hun routers al toegepast en komen de sessies gelijk op. Deze kunnen we bekijken via de meegeleverde vtysh tool die ook een enkel commando accepteert. We kijken naar de summary (of de sessies up zijn) en naar de ontvangen routes:
root@server1:~$ vtysh -c "show ip bgp summ"
IPv4 Unicast Summary (VRF default):
BGP router identifier 10.99.75.3, local AS number 65015 vrf-id 0
BGP table version 2
RIB entries 1, using 184 bytes of memory
Peers 2, using 1446 KiB of memory
Peer groups 1, using 64 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.99.75.1 4 65001 494 471 0 0 0 01:18:00 1 (Policy) r1
10.99.75.2 4 65001 500 471 0 0 0 01:18:08 1 (Policy) r2
Total number of neighbors 2
root@server1:~# vtysh -c "show ip bgp"
BGP table version is 2, local router ID is 10.99.75.1, vrf id 0
Default local pref 100, local AS 65015
Status codes: s suppressed, d damped, h history, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*= 0.0.0.0/0 10.99.75.1 0 65001 i
*> 10.99.75.2 0 65001 i
Het enige wat resteert is het uitschakelen van de statisch ingestelde default-gateway. Deze kan in /etc/netplan/00-installer-config.yaml gecommentarieerd worden
#routes:
#- to: default
# via: 10.99.75.1
Nu kan je via netplan apply de configuratie toepassen maar het beste is een eenvoudige herstart van de gehele server. Na herstart kan je weer bij de server. Validatie is dan niet nodig maar je ziet:
root@server1:~$ ip route
default nhid 10 proto bgp metric 20
nexthop via 10.99.75.2 dev ens192 weight 1
nexthop via 10.99.75.1 dev ens192 weight 1
10.99.75.0/29 dev ens192 proto kernel scope link src 10.99.75.3
Mocht je deze BGP-setup op een bestaande server installeren, vergeet dan niet poort tcp/179 toe te voegen in je firewall voor communicatie met de routers.
Vanuit de Linux wereld bestaat de term ‘cron’. Deze term komt vanuit het oude Grieks en het betekend tijd. Vanuit oudsher was op Linux de mogelijkheid om op een paar verschillende manieren een scheduled job te starten, zijnde een table (vandaar crontab):
Dus elke maandag om 1 minuut over 12 uur word onder de naam j.doe het script uitgevoerd. Het enige verschil met de user cron (crontab -e (edit) of crontab -l (list) is dat de username niet opgevoerd hoeft te worden omdat het in die userspace opereert.
Sinds al een lange poos is de Linux wereld over aan het stappen naar systemd (nouja, is al overgestapt). Deze architectuur en manier van werken is in diverse opzichten een flinke verbetering van de oude init.d scripts/services en dus crontab. Nu is dat geen nieuwtje maar het gebeurt gewoon te makkelijk om “even een crontabje” te zetten.
Systemd staat je toe zelf eenvoudig services te schrijven maar ook targets én timers. De timer functie zoom ik iets meer op in, daar ik vind het een veel betere plek is voor scheduled jobs. Hier komen namelijk ook meer voordelen bij, te denken aan logging/auditing, controle van de jobs, error afhandeling en complexe situaties om pas te starten als ‘iets’ beschikbaar is, of nadat een ander proces succesvol is gestart. De oude cron methode is meer als UDP op het netwerk: fire and forget.
Een voorbeeld is een soort disk-check die elk half uur de vrije ruimte opvraagt en boven, zeg, 75% gebruik een email uitstuurt naar de beheerder. Dit kan eenvoudig in een cron maar we maken er nu een service van.
/usr/lib/systemd/system/diskcheck.service
[Unit]
Description=Disk space check
[Service]
ExecStart=/usr/local/bin/syschk -d
De timer binnen systemd. Deze naam moet overeenkomen met de service.
/usr/lib/systemd/system/diskcheck.timer
[Unit]
Description=Disk space check every 30 minutes
[Timer]
OnCalendar=*:0/30
Persistent=true
[Install]
WantedBy=timers.target
En deze timer schakelen we in: systemctl daemon-reload && systemctl enable diskcheck.timer
Om te zien of alles goed werkt kan je eenvoudig een paar commando’s uitvoeren:
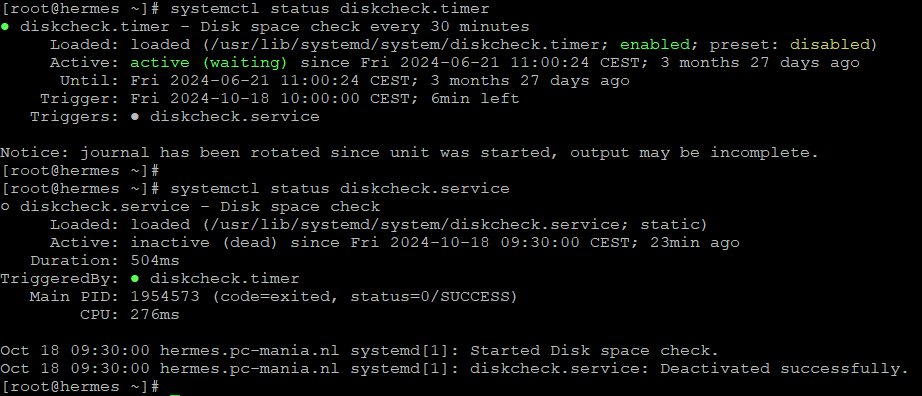
systemctl status diskcheck.service
systemctl status diskcheck.timer
En zo heb je dus een heel simpel iets als nog heel simpel gemaakt binnen de huidige systemd wereld met voordelen van logging en uiteraard als je wil dat de service uit gezet moet worden:
systemctl disable diskcheck.timer
Een andere optie is een service te maken die alleen actief is bij opstarten (on-boot). Dit voorbeeld start een script (met 2 command line opties) dat pas start als het netwerk online is én postfix gestart is. Waarom? Als de ‘syschk’ iets afwijkends detecteert moet het een email kunnen uitsturen.
Met name de After regels zijn in dit geval waarmee het gestuurd word.
Als je besluit dat het een background daemon of iets dergelijk moet worden, dan kan dat ook op deze manier maar dan moet je in jouw proces of script wel het altijd aan laten. Denk aan een lowlevel ‘while true’ loop (maar denk aan je cpu cylcles ;).
Het nakijken van statussen en logs is bijvoorbeeld met eerder genoemde systemctl commando. Echter is er ook vanuit het Linux eco systeem een andere optie: journalctl.
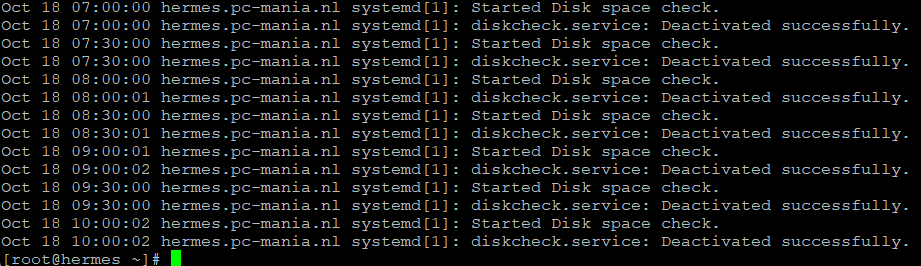
journalctl -eu diskcheck.service
De opties zijn flink en de gekozen 2 zijn eenvoudig de eerste om mee te beginnen. De ‘-e’ is pager-end, of wel het laatste stukje en de ‘-u’ is de betreffende unit. In dit voorbeeld de eerder gemaakte diskcheck.service.
Uiteraard zijn er veel meer opties met journalctl om in te zoomen op bijv. tijdsvakken en nog meer. Zie ook de ‘manpages’.
Zo makkelijk als het lijkt om een service, met timer of niet, te maken is, een veelal vergeten aspect, natuurlijk wel even denken aan veiligheid. De systemd services kunnen en mogen veel, ‘out-of-the-box’. Dat is voor een lokaal servertje thuis niet direct een probleem maar een webserver of waar gevoelige data verwerkt kan worden is dan een interessant object. Als je daar, op welke manier dan ook, gebruik kan maken van zwakheden dan is dat als kwaadwillende top. Ik ga hier in dit artikel niet dieper op in maar verdiep gerust even in de materie: